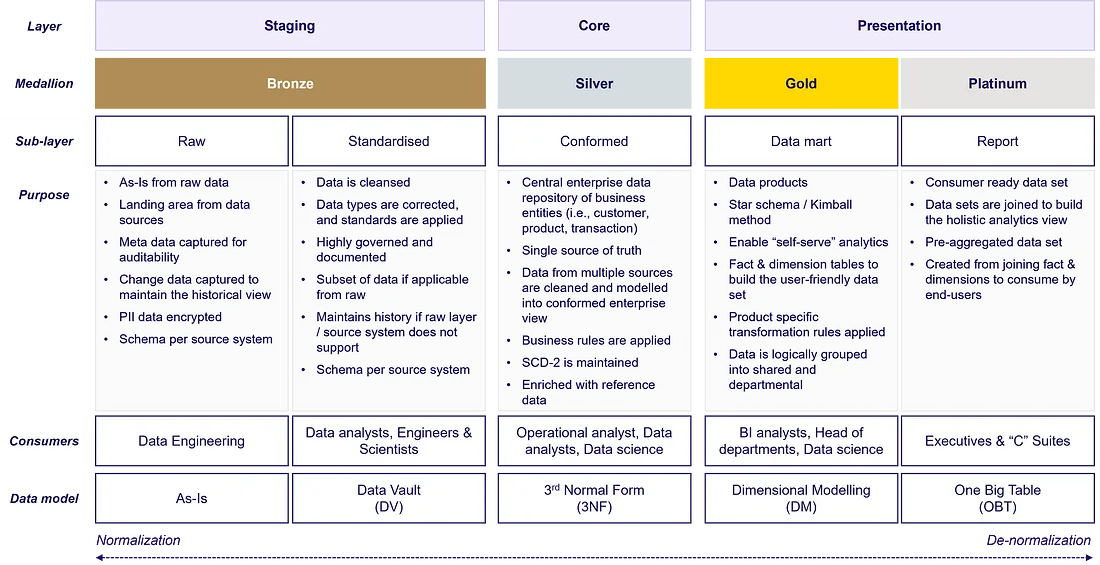
Principles of Data layers in Data Platform
Data organizing principles are vital when we build the data platform to enable data maturity for the business.
Data management is one of the key aspects of the data platform's build. Most of the time, analysts build their own transformation logic and build reports after accessing the data from the platform. As a result, data is siloed.
Data layers help to ensure that the data is organized in a way that is
- consistent
- reliable
- reduced data redundancy
- agility
- and accessible.
This makes it easier for businesses to use data to make informed decisions.
Data layers: deep dive
Analogy
Throughout this blog, we use the analogy of how restaurants serve food to their customers after they purchase ingredients.
Medallion architecture — Does it matter? Not at all. Technically Bronze, Silver and Gold layer do not have distinct features to leverage. It is the data design pattern introduced by Databricks and we use it for naming convention which can be easily understandable. We introduced the Platinum layer!
Staging
The staging layer is the first level of data storage on a data platform. It stores data in a format that is closely aligned with the data structure of the operational system. The staging layer is divided into two sublayers: the raw layer and the standardized layer.
Raw
- Data from source systems is loaded into the raw layer in the destination data warehouse. The destination can be Snowflake, Google BigQuery, AWS RedShift, Delta Lake, or AWS S3.
- ELT tools such as Fivetran, Stitchdata, Airbyte, and custom connectors can be used to load the data from the source systems into the destination.
- The raw layer should be treated with extra care to ensure that no users or processes modify the schema and table structure. The data engineering team should own the raw layer since its state is managed by ELT tools in the modern data stack.
- Data is loaded to the raw layer as-is, with additional metadata attributes such as data_loaded_at and file_name
- Each source system’s data should have its own schema in the raw layer for auditing purposes. Schema names should follow the following naming convention: _The table name in the raw layer should maintain the source system table name.
Analogy
As a first step to preparing the food in restaurants, we need to collect the ingredients from suppliers. It is similar to collecting data from operational systems. This is where data contracts play a critical role in ensuring,
1) Arrival of data as expected on the platform. Any availability, or accessibility issues in the operational system impact the timely delivery of data to businesses (consumers).
2) Both parties need to agree on how data (ingredients) can be agreed upon between two parties’ data producer and the platform team (supplier and restaurants) on an SLA.
3) Changes to the structure of the data (changes to the ingredients) should be notified to the platform team (restaurants). Otherwise restaurants cannot make the food as per menu
Standardised
Similar to raw layer with following definitions,
- Right data type: ELT tools do not always store columns in the right data type when they load data. We had challenges with a few ELT tools that loaded the data into VARCHAR in your destination.
- Meta-data first: Tables and attributes in your destination should have a description to enable analysts to easily discover and access the data. When you use the data catalog tool, meta data can be easily sourced from your destination. Also, meta data should be centrally managed in your warehouse.
- Metadata can also be used to classify your data into PII categories and more. Definitions for the data need to be defined by the data owner in the business, working with the data governance team.
- Manage history: There are instances where you cannot maintain the history of changes from your sources in the raw layer due to the lack of a way to identify the delta and the limitations of your data pipeline. It is recommended to keep the history of changes as early as possible in the data layer.
- Subset of data (optional): Unless there is a need for the data to be used by analysts to build ad-hoc analyses, there is no need to bring the data into standardised layer.
Analogy
Once the ingredients (data) is landed into restaurants from the data engineers. data should be governed and well organised in the inventory with additional meta data i.e., when ingredients loaded, units, time of arrival and right level of logical group for cooking team (analytical engineering) to consume the ingredients to make the tasty food!
Do we need Data Vault?
Data vault definitely helps to organise the data using hub, link and satellite for large number of systems and enterprise data. If you are a less matured & small data analytics team who is beginning the data journey, you don’t need to adopt to data vault pattern. Please keep it in your parking lot list to revisit in future.
Core
The core layer is the transition layer used to integrate data from multiple sources into conformed entities.
Prep
Subset of the core layer, which is the integration layer to model the data into a consistent structure.
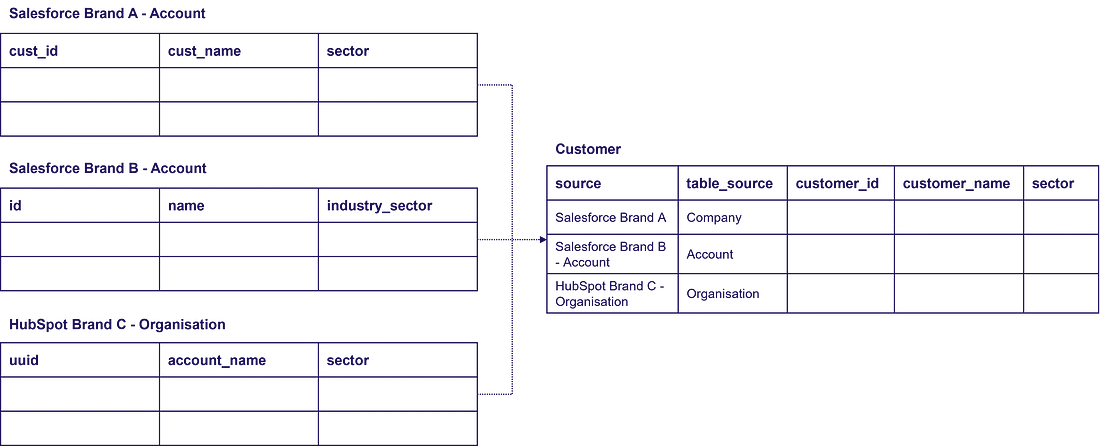
What exactly does this layer do?
- identify the attributes from multiple data sources and map them to consistent names
- identify the business keys
- union all the data into single model
- apply universal cleansing rules
Analogy
Before cooking, kitchen porter prepares ingredients including cutting the vegetables, peeling the apple and grating the cheese. Then they will keep the ingredients ready for recipes
Conformed
Business rules and complex transformations are applied at the conformed layer to build the enterprise data domains. Conformed entities are commonly understood and used across organizations.
Data sets will be treated as master data and a single source of truth. It is the entry point for businesses to access the enterprise view of their data.
Analogy
Chefs are now ready to cook the food to serve to the customers. It is the key role in the restaurants and there will be different chefs to make the recipes. Similarly in the data platform, analytical engineering build the models to serve the data with the help of departmental analysts.
Reference data
How do fit the reference data in the data layers? Reference data is the small set of data set which enriches the data. Sometimes this can be static mapping tables which is created for analytical purpose. We recommend to keep the reference data in core layer and use them to build the conformed layer.
Presentation
Business intelligence analysts and data scientist teams access data products and consumption-ready datasets to create dashboards and insights.
Data mart
Star schema model to store the data in fact and dimension tables. Follows the Kimball methodology, which is optimized for analytical purposes.
Dimensional modelling allows the business analyst to build the visualisation rapidly to serve the insights to “C-suite” executives and stakeholders
Analogy
Once the recipes are ready, next step is to serve the food. Data mart is similar to buffet for the customers to serve themselves. All the recipes are placed in structured and logical group for the consumers to serve themselves. Data is well structured and documented in data mart layer to build the insights quickly.
Report
Datasets are created from the data mart layer and sometimes from the staging or conformed layer, which is completely denormalized.
- Pre-joined and Pre-aggregated datasets: Executives can access the data directly and no joins are required to create the insights
Analogy
It is the final stage where servers (data analysts) from restaurant serves the desired food to the customers (executives and stakeholders). Data analysts build the insights for the executives in the business who can just access the insights to make the decision.
How can we make the data platform a success?
- Continual sessions with analysts and business required to make them understand the data layers and its rationale
- Monitoring usage history allows data platform team to measure how frequently data is accessed, frequently used dataset and long-running queries to make pro-active steps to improve the performance of platform
- Agility enables the business to trust in the foundation of the data platform, which should be sustainable, scalable and reliable
- Continual feedback and iteration help the data platform team identify the challenges from data analyst team and conduct sessions if required to increase the usage of data platform